Raft Consensus
Distributed consensus algorithm implementation in Go. Raft keeps a cluster of machines in agreement on a sequence of operations. It makes a replicated log behave like a single reliable log, even when some nodes crash or restart.
Language
Go
Type
Consensus
Status
Complete
Tech Stack
Technologies Used
Core Implementation
Key Features
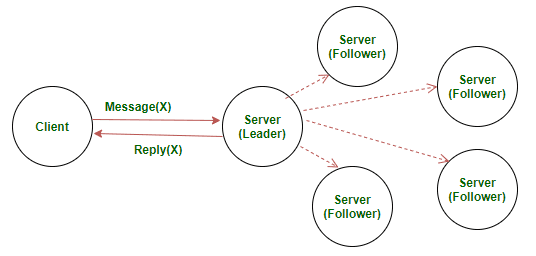
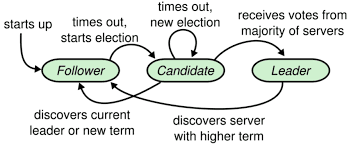
Leader Election
Nodes start as followers. On timeouts they become candidates, vote, and elect a leader that coordinates the cluster.
Log Replication
The leader appends client commands to its log and replicates them to followers via AppendEntries RPCs until a majority acknowledges.
Safety & Commitment
Entries are committed only when stored on a majority and applied in order to the state machine, guaranteeing linearizable results.
Visual Preview
Screenshots
Deep Dive
Project Case Study
Technical details and challenges
The Challenge
Distributed consensus is fundamental to reliable systems but notoriously difficult to implement correctly. Raft provides understandable consensus but requires careful handling of leader election, log replication, network partitions, and node failures. The challenge was implementing a production-quality Raft consensus algorithm in Go with proper state machine safety and crash recovery.
The Solution
Implemented complete Raft protocol following the original paper. The system handles leader election with randomized timeouts, log replication with AppendEntries RPCs, and safe log commitment with majority quorums. Nodes persist critical state to survive crashes. The implementation includes comprehensive testing for network partitions, leader failures, and concurrent client operations.
Technical Deep Dive
Go's goroutines handle concurrent election timers and RPC handlers. Persistent storage ensures state survives crashes. The leader election algorithm uses randomized timeouts to prevent split votes. Log replication ensures all nodes maintain identical command sequences. Commitment requires majority acknowledgment for safety. The implementation passed rigorous distributed systems tests including network partitions and cascading failures.
Results & Impact
Successfully implemented Raft consensus meeting all safety and liveness properties. The system handles leader failures, network partitions, and node crashes correctly. Comprehensive test suite validates correctness under adversarial conditions. The project received excellent marks for demonstrating deep understanding of distributed consensus algorithms and practical systems programming in Go.